Co-design Approach
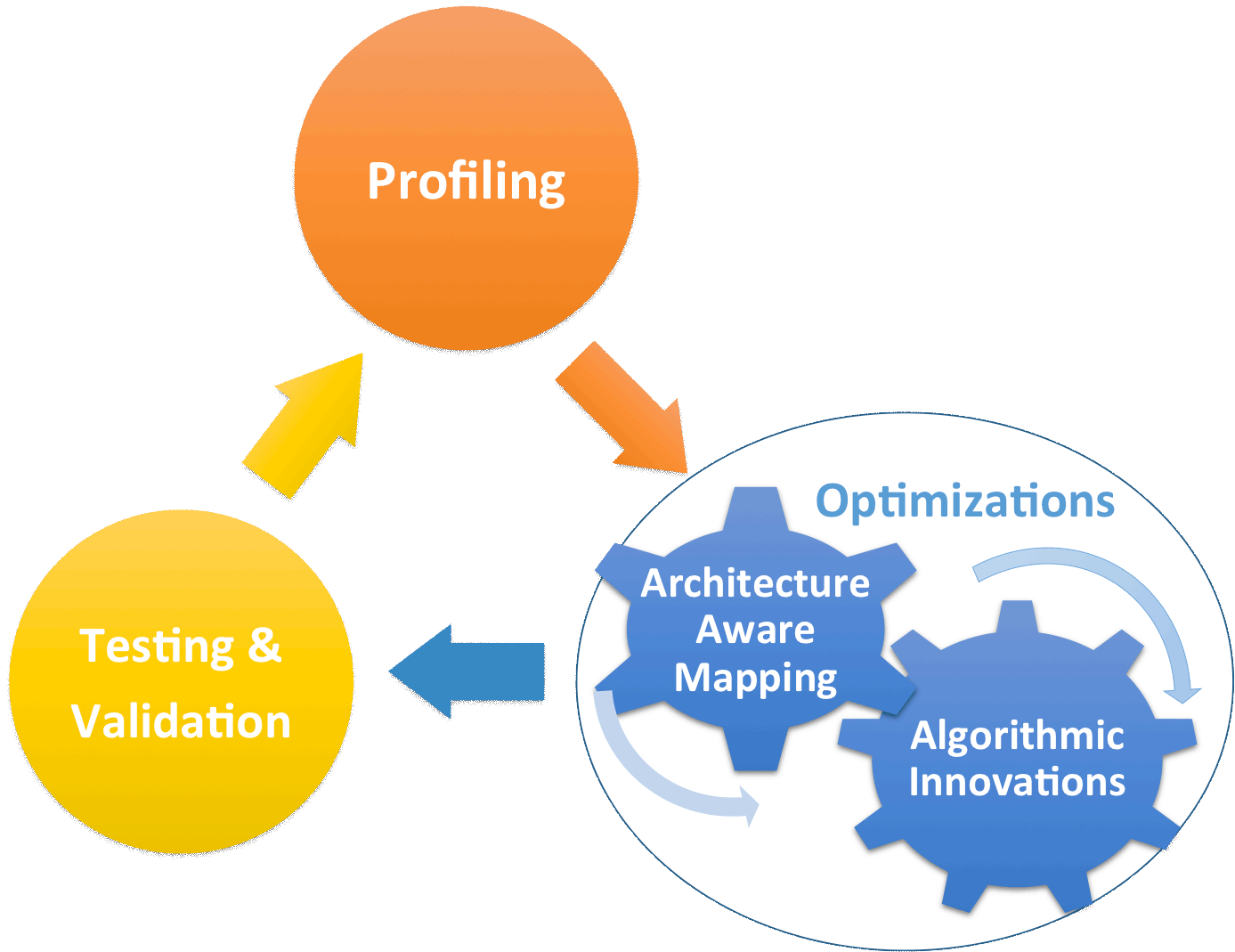 As noted in the project overview, exploiting the full potential of emerging heterogeneous architectures is challenging and often requires both architecture-aware optimizations and algorithmic innovations. This challenge frequently results in the implicit use of a hardware/software co-design approach, pairing domain scientists with computer scientists or other optimization experts. While the practices inherent in the process are well-known for optimization veterans, we seek to distill the essence of the process into a formula or recipe that can guide the process of creating accelerated applications de novo or from legacy code. Based on first-hand experiences performing manual co-design on CFD codes for this project, as well as personal histories in domains such as Molecular Modeling, Neutron Transport, Bioinformatics, and Cosmology, we have devised an iterative recipe in three parts: Profiling and Testing, Architecture Aware Mapping and Optimizations, and Algorithmic Innovation.
As noted in the project overview, exploiting the full potential of emerging heterogeneous architectures is challenging and often requires both architecture-aware optimizations and algorithmic innovations. This challenge frequently results in the implicit use of a hardware/software co-design approach, pairing domain scientists with computer scientists or other optimization experts. While the practices inherent in the process are well-known for optimization veterans, we seek to distill the essence of the process into a formula or recipe that can guide the process of creating accelerated applications de novo or from legacy code. Based on first-hand experiences performing manual co-design on CFD codes for this project, as well as personal histories in domains such as Molecular Modeling, Neutron Transport, Bioinformatics, and Cosmology, we have devised an iterative recipe in three parts: Profiling and Testing, Architecture Aware Mapping and Optimizations, and Algorithmic Innovation.
Validation
The most critical aspect of accelerating an existing code, or designing a new code from scratch is that the resulting code provides accurate results. It doesn't matter how fast it runs if the output cannot be trusted. Thus a mechanism and criteria to validate incremental changes to the code must be established, usually by the domain scientists and mathematicians. One approach we have used is to validate a canonical baseline of one's code against an independent solution, then compare subsequent experimental versions to this original - the “Gold Standard” approach. This validation should be as low-overhead to perform as reasonable, as it should be performed after every optimization pass to ensure no regressions have been introduced. We have seen manual comparison of convergence behavior, computer-aided visualization of results, and automatic relative error calculations versus a gold standard all used as low-cost validation methods.
Profiling
Second-most critical to the process of co-designing accelerated code is having a constant awareness of where time is being spent. The most significant performance gains often come by eliminating or significantly reducing the bottlenecks which make up the most significant portion of total time to solution. Such communication and computation bottlenecks are identified with some form of profiling, either via an external profiling tool, or via hand-instrumentation of the code. Raw time cost of a particular method is core factor to consider from profiling output, however other metrics, such as amount of disk I/O, cache hits and misses, and architecture-specific metrics such as GPUs' divergent branches often provide more directly useful insights. Whether via an external tool or manual instrumentation, profiling (re)directs programmer attention to the most critical regions of code at a given point in the development cycle and after validation should be performed after every optimization to quantify its effects on the program and time to solution as a whole.
Optimization
Optimization of an application to a target architecture generally exhibits one of two forms at any given moment in the development process; either existing algorithmic approaches and data structures are tuned to better map to the accelerator devices' performance characteristics, or algorithms which are poorly-suited for the device are redesigned from scratch, or replaced with an existing solution. In co-design approaches, both forms are generally present, and frequently interleaved, with architecture experts generally playing a larger role in tuning and domain experts playing a larger role in algorithmic innovation. (This is not to say they're mutually-exclusive, in fact for the process to reasonably be considered co-design, both sides must be involved in both forms of optimization and must understand the methods used, relying on cross-domain knowledge transfer.)
Architecture-Aware Tuning
Accelerator devices often have unique hardware behaviors requiring computations to take specific structural forms, which often diverge significantly from the forms most optimal for traditional CPU execution. For example, classical CPU optimization often dictates that all data for an item of work be contiguous in memory (Array-of-Structs) for better cache locality; however, in GPU platforms, the extreme SIMD parallelism dictates instead that individual variables for consecutive work items be contiguous in memory (Struct-of-Arrays). Architecture experts generally have honed an intrinsic knowledge of many best practices for programming a given device and, by recognizing red flags in profiling data, can quickly identify low-hanging performance gains and re-tune the relevant code sections.
Algorithmic Innovation
Simple tuning can often achieve impressive performance gains over direct implementations of accelerated code. However, an incredibly powerful optimization tactic, both in the context of heterogeneous computing and traditional CPU-only computing is to purpose-build algorithms that capitalize on one or more unique features of the problem domain being solved to either significantly reduce the aggregate workload, dramatically increase parallelism that can be exploited by the device, or both. Given the focus on the science and mathematics of the problem domain, these efforts are most frequently led by domain experts
